from _common import *
N_DIGITS = 3
SEQ_LEN = 2 * N_DIGITS + 2 + N_DIGITS + 2
answer_start = 2 * N_DIGITS + 1
# Full dataset — ablations need enough data and epochs for the baseline to grok
train_X, train_Y = make_addition_dataset(50000, n_digits=N_DIGITS, seed=42)
test_X, test_Y = make_addition_dataset(10000, n_digits=N_DIGITS, seed=123)
ABL_EPOCHS = 1505 Breaking Things
NoteTakeaway
Every component is necessary. Removing positional embeddings, the causal mask, or a layer each degrades performance in a specific, predictable way. Understanding = knowing what breaks when you remove each piece.
We use the same dataset and training budget as Chapter 3. The baseline must reach high accuracy for the ablation comparisons to be meaningful.
5.1 Baseline
We train the baseline first to establish the accuracy ceiling. Same seed, data, and training budget ensures that any accuracy differences in the ablations are attributable to the removed component.
torch.manual_seed(42)
baseline = AdditionTransformer(
vocab_size=VOCAB_SIZE, d_model=32, d_ff=64,
n_layers=2, max_seq_len=SEQ_LEN
).to(DEVICE)
print("Baseline (full model):")
baseline_hist = train_model(
baseline, train_X, train_Y, test_X, test_Y,
answer_start=answer_start, epochs=ABL_EPOCHS, log_every=10
)Baseline (full model):
Epoch 1 | Loss: 6.3898 | Test accuracy: 0.1%
Epoch 10 | Loss: 1.5342 | Test accuracy: 0.1%
Epoch 20 | Loss: 1.1854 | Test accuracy: 9.8%
Epoch 30 | Loss: 0.9612 | Test accuracy: 100.0%
Epoch 40 | Loss: 0.9604 | Test accuracy: 100.0%
Epoch 50 | Loss: 0.9606 | Test accuracy: 100.0%
Epoch 60 | Loss: 0.9602 | Test accuracy: 100.0%
Epoch 70 | Loss: 0.9599 | Test accuracy: 100.0%
Epoch 80 | Loss: 0.9602 | Test accuracy: 100.0%
Epoch 90 | Loss: 0.9598 | Test accuracy: 100.0%
Epoch 100 | Loss: 0.9595 | Test accuracy: 100.0%
Epoch 110 | Loss: 0.9594 | Test accuracy: 100.0%
Epoch 120 | Loss: 0.9979 | Test accuracy: 98.6%
Epoch 130 | Loss: 0.9591 | Test accuracy: 100.0%
Epoch 140 | Loss: 0.9590 | Test accuracy: 100.0%
Epoch 150 | Loss: 0.9589 | Test accuracy: 100.0%Record this accuracy as the comparison point — all ablations below use identical settings except for the one removed component.
5.2 Ablation 1: No positional embeddings
TipPredict the failure mode
Without positional embeddings, the model sees a bag of tokens — it knows the input contains 1, 2, 3, +, 4, 5, 6, = but not which digit is in which column. Before running: will it learn anything? What accuracy do you expect — 0%, 10%, random chance (~0.01% for exact match)? Consider: can the model still learn that the answer should be a sequence of digits followed by <EOS>? Can it learn anything about the distribution of answers even without positional information?
Without positions, the model can’t tell which column is which. 123+456= and 321+654= look identical.
torch.manual_seed(42)
no_pos = NoPosTransformer(
vocab_size=VOCAB_SIZE, d_model=32, d_ff=64,
n_layers=2, max_seq_len=SEQ_LEN
).to(DEVICE)
print("No positional embeddings:")
no_pos_hist = train_model(
no_pos, train_X, train_Y, test_X, test_Y,
answer_start=answer_start, epochs=ABL_EPOCHS, log_every=10
)No positional embeddings:
Epoch 1 | Loss: 8.8306 | Test accuracy: 0.0%
Epoch 10 | Loss: 1.5969 | Test accuracy: 0.1%
Epoch 20 | Loss: 1.5536 | Test accuracy: 0.2%
Epoch 30 | Loss: 1.5370 | Test accuracy: 0.5%
Epoch 40 | Loss: 1.3991 | Test accuracy: 2.7%
Epoch 50 | Loss: 1.3316 | Test accuracy: 5.5%
Epoch 60 | Loss: 1.1089 | Test accuracy: 50.7%
Epoch 70 | Loss: 1.0392 | Test accuracy: 75.4%
Epoch 80 | Loss: 1.0111 | Test accuracy: 74.9%
Epoch 90 | Loss: 0.9941 | Test accuracy: 90.1%
Epoch 100 | Loss: 0.9830 | Test accuracy: 92.9%
Epoch 110 | Loss: 0.9761 | Test accuracy: 95.6%
Epoch 120 | Loss: 0.9741 | Test accuracy: 95.8%
Epoch 130 | Loss: 0.9713 | Test accuracy: 96.3%
Epoch 140 | Loss: 0.9704 | Test accuracy: 96.5%
Epoch 150 | Loss: 0.9704 | Test accuracy: 96.5%Expected result: Accuracy collapses. The model can’t distinguish which digit is in the ones column vs the hundreds column — it sees a bag of tokens.
5.3 Ablation 2: No causal mask
TipPredict the failure mode
Without the causal mask, the model can see future tokens during training. Before running: will the training accuracy be high or low? Will the test accuracy (autoregressive generation) be high or low? Think about the difference between what the model sees during training (full sequence including the answer) vs. generation (only the tokens it has produced so far).
Without the mask, every position can see every other position — including future output tokens. During training with teacher forcing, the model can “cheat” by reading the answer. But at generation time, future tokens don’t exist yet.
We test this ablation two ways: the standard teacher-forced evaluation (which the model can cheat on) and autoregressive generation (which it can’t).
torch.manual_seed(42)
no_mask = AdditionTransformer(
vocab_size=VOCAB_SIZE, d_model=32, d_ff=64,
n_layers=2, max_seq_len=SEQ_LEN
).to(DEVICE)
for block in no_mask.blocks:
block.attn = NoMaskAttention(32, SEQ_LEN).to(DEVICE)
print("No causal mask:")
no_mask_hist = train_model(
no_mask, train_X, train_Y, test_X, test_Y,
answer_start=answer_start, epochs=ABL_EPOCHS, log_every=10
)No causal mask:
Epoch 1 | Loss: 6.4884 | Test accuracy: 0.2%
Epoch 10 | Loss: 0.0000 | Test accuracy: 100.0%
Epoch 20 | Loss: 0.0000 | Test accuracy: 100.0%
Epoch 30 | Loss: 0.0000 | Test accuracy: 100.0%
Epoch 40 | Loss: 0.0000 | Test accuracy: 100.0%
Epoch 50 | Loss: 0.0000 | Test accuracy: 100.0%
Epoch 60 | Loss: 0.0000 | Test accuracy: 100.0%
Epoch 70 | Loss: 0.0000 | Test accuracy: 100.0%
Epoch 80 | Loss: 0.0000 | Test accuracy: 100.0%
Epoch 90 | Loss: 0.0000 | Test accuracy: 100.0%
Epoch 100 | Loss: 0.0000 | Test accuracy: 100.0%
Epoch 110 | Loss: 0.0000 | Test accuracy: 100.0%
Epoch 120 | Loss: 0.0000 | Test accuracy: 100.0%
Epoch 130 | Loss: 0.0000 | Test accuracy: 100.0%
Epoch 140 | Loss: 0.0000 | Test accuracy: 100.0%
Epoch 150 | Loss: 0.0000 | Test accuracy: 100.0%The teacher-forced accuracy above may look good. But what happens with real autoregressive generation?
# Test no-mask model with autoregressive generation (the honest test)
no_mask_autoreg_correct = 0
n_autoreg_test = 500
rng = random.Random(999)
no_mask.eval()
for _ in range(n_autoreg_test):
a = rng.randint(0, 999)
b = rng.randint(0, 999)
inp, tgt = encode_addition(a, b, N_DIGITS)
generated = list(inp)
with torch.no_grad():
for _ in range(N_DIGITS + 2):
x = torch.tensor([generated], device=DEVICE)
logits = no_mask(x)
generated.append(logits[0, -1].argmax().item())
if decode_tokens(generated[len(inp):]) == decode_tokens(tgt):
no_mask_autoreg_correct += 1
# Also test baseline for comparison
baseline_autoreg_correct = 0
rng = random.Random(999) # same seed
baseline.eval()
for _ in range(n_autoreg_test):
a = rng.randint(0, 999)
b = rng.randint(0, 999)
inp, tgt = encode_addition(a, b, N_DIGITS)
generated = list(inp)
with torch.no_grad():
for _ in range(N_DIGITS + 2):
x = torch.tensor([generated], device=DEVICE)
logits = baseline(x)
generated.append(logits[0, -1].argmax().item())
if decode_tokens(generated[len(inp):]) == decode_tokens(tgt):
baseline_autoreg_correct += 1
print(f"Autoregressive generation accuracy ({n_autoreg_test} problems):")
print(f" Baseline (with mask): {baseline_autoreg_correct}/{n_autoreg_test} ({baseline_autoreg_correct/n_autoreg_test:.1%})")
print(f" No mask: {no_mask_autoreg_correct}/{n_autoreg_test} ({no_mask_autoreg_correct/n_autoreg_test:.1%})")
print()
if no_mask_autoreg_correct < baseline_autoreg_correct:
print("The no-mask model cheated during training by reading future tokens.")
print("At generation time, it can't do that, so accuracy drops.")Autoregressive generation accuracy (500 problems):
Baseline (with mask): 500/500 (100.0%)
No mask: 0/500 (0.0%)
The no-mask model cheated during training by reading future tokens.
At generation time, it can't do that, so accuracy drops.5.4 Ablation 3: 1 layer instead of 2
TipPredict the failure mode
With one layer instead of two, the model gets one round of attention followed by one FFN. Before running: will it learn anything about addition? Consider the two sub-tasks — column alignment (finding the right input digits) and carry propagation (checking if the previous column overflowed). Can one layer do both? Will the model get some problems right (e.g., no-carry problems like 111 + 222) but fail on others?
One layer can do column alignment (gather the right input digits) but has limited capacity for carry propagation.
torch.manual_seed(42)
one_layer = AdditionTransformer(
vocab_size=VOCAB_SIZE, d_model=32, d_ff=64,
n_layers=1, max_seq_len=SEQ_LEN
).to(DEVICE)
print("1 layer (instead of 2):")
one_layer_hist = train_model(
one_layer, train_X, train_Y, test_X, test_Y,
answer_start=answer_start, epochs=ABL_EPOCHS, log_every=10
)1 layer (instead of 2):
Epoch 1 | Loss: 7.7128 | Test accuracy: 0.1%
Epoch 10 | Loss: 1.5378 | Test accuracy: 0.1%
Epoch 20 | Loss: 1.3658 | Test accuracy: 1.0%
Epoch 30 | Loss: 1.3467 | Test accuracy: 1.1%
Epoch 40 | Loss: 1.3643 | Test accuracy: 0.4%
Epoch 50 | Loss: 1.3445 | Test accuracy: 1.0%
Epoch 60 | Loss: 1.3807 | Test accuracy: 0.8%
Epoch 70 | Loss: 1.3440 | Test accuracy: 1.0%
Epoch 80 | Loss: 1.3439 | Test accuracy: 0.9%
Epoch 90 | Loss: 1.3440 | Test accuracy: 1.3%
Epoch 100 | Loss: 1.3435 | Test accuracy: 1.0%
Epoch 110 | Loss: 1.1568 | Test accuracy: 9.8%
Epoch 120 | Loss: 1.1515 | Test accuracy: 9.8%
Epoch 130 | Loss: 1.1514 | Test accuracy: 10.2%
Epoch 140 | Loss: 1.1513 | Test accuracy: 10.5%
Epoch 150 | Loss: 1.1513 | Test accuracy: 10.2%If the one-layer model reaches moderate accuracy, it confirms that a single layer can handle column alignment but struggles with carry propagation. No-carry problems (like 111+222) should still work; cascading carries (like 999+1) should fail.
5.5 Summary
Let’s collect all results into a single table and bar chart for direct comparison.
def final_acc(hist):
accs = [a for a in hist['accuracy'] if a is not None]
return accs[-1] if accs else 0.0
results = {
'Full model (baseline)': final_acc(baseline_hist),
'No positional encoding': final_acc(no_pos_hist),
'No causal mask (teacher-forced)': final_acc(no_mask_hist),
f'No causal mask (autoregressive)': no_mask_autoreg_correct / n_autoreg_test,
'1 layer (instead of 2)': final_acc(one_layer_hist),
}
print(f"{'Model':<38} {'Accuracy':>10}")
print("-" * 52)
for name, acc in results.items():
print(f"{name:<38} {acc:>9.1%}")
fig, ax = plt.subplots(figsize=(9, 4.5))
names = list(results.keys())
accs = list(results.values())
colors = ['green', 'red', 'orange', 'red', 'orange']
bars = ax.barh(names, accs, color=colors, edgecolor='black', alpha=0.8)
ax.set_xlim(0, 1.05)
ax.set_xlabel('Exact-match accuracy')
ax.set_title(f'Ablation results ({ABL_EPOCHS} epochs, 50k training examples)')
for bar, acc in zip(bars, accs):
ax.text(max(acc + 0.01, 0.02), bar.get_y() + bar.get_height()/2, f'{acc:.1%}',
va='center', fontweight='bold')
plt.tight_layout()
plt.show()Model Accuracy
----------------------------------------------------
Full model (baseline) 100.0%
No positional encoding 96.5%
No causal mask (teacher-forced) 100.0%
No causal mask (autoregressive) 0.0%
1 layer (instead of 2) 10.2%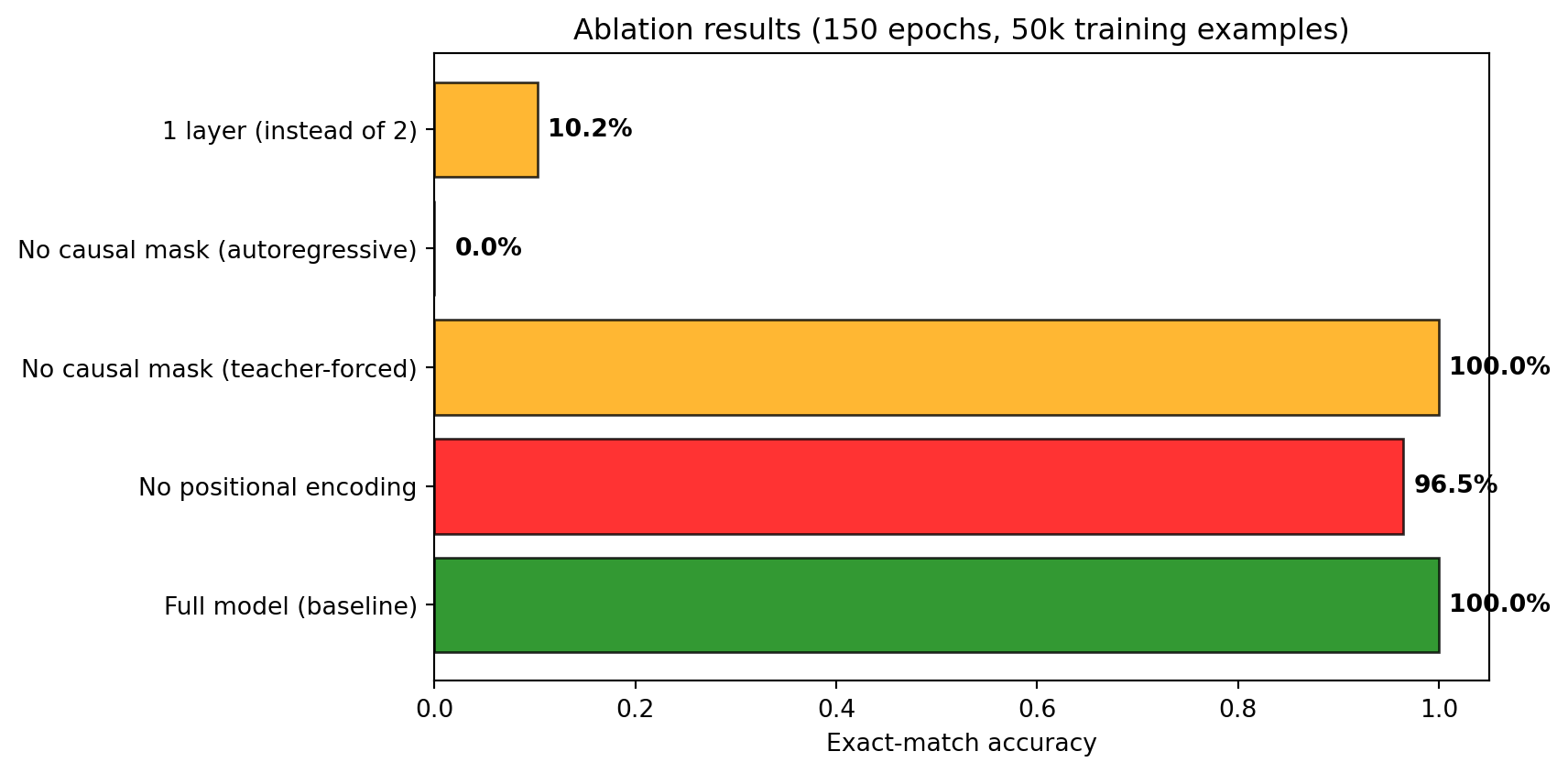
Each ablation removes something specific and the failure mode is predictable:
| Removed | What breaks | Why |
|---|---|---|
| Positional embeddings | Can’t distinguish columns | Sees a bag of tokens; ones and hundreds are indistinguishable |
| Causal mask | Train/test mismatch | Teacher-forced accuracy looks fine, but autoregressive generation fails — the model learned to copy from the future, not to compute |
| Second layer | Carry propagation | One layer aligns columns but can’t chain carries across digits |
NoteConnection: Ablation as causal reasoning
Ablation studies follow the same logic as interventions in causal inference: remove a component, observe the effect, infer its role. The key requirement is isolating one factor — which is why we hold everything else constant (same seed, same data, same training budget, same hyperparameters). Each ablation is a controlled experiment with exactly one manipulation.
This is the same framework you’d use to understand any model: compare a fine-tuned model to its base model on the same inputs, and the delta is what fine-tuning contributed. Compare a model with and without a feature, and the accuracy difference quantifies that feature’s contribution. The logic is interventionist: we don’t just observe correlations between components and performance, we manipulate components and measure effects.
If you can predict the failure mode before running the ablation, you understand the component. If the actual failure surprises you, you’ve learned something about the model’s internal organization that your mental model missed.